
Anthropic가 2025년 11월 24일(현지 시각) 플래그십 모델 Claude Opus 4.5를 공개했습니다. 이 모델은 자사 설명과 클라우드 파트너 발표에 따르면 코딩, 에이전트(workflow), 컴퓨터 사용 영역에서 자기들이 테스트해본 모델 중 최고 성능을 보이며, 소프트웨어 엔지니어링 벤치마크 SWE-bench Verified에서 **정확도 80.9%**를 기록했다고 합니다. 가격은 이전 Opus 4 대비 약 3분의 1 수준으로 인하되어, “고성능+비용 절감” 조합이 얼마나 실제 업무에 영향을 줄지 주목받고 있습니다.
1. 무엇이 발표됐나? – 플래그십 업그레이드의 핵심
Anthropic는 공식 뉴스 페이지 **〈Introducing Claude Opus 4.5〉**에서 Opus 4.5를 “지금까지 만든 모델 중 가장 지능적인(most intelligent) 모델”이자, 코딩·에이전트·복잡한 컴퓨터 작업에서 새로운 기준을 세우는 모델로 소개합니다. Anthropic+1
Times of India 등 주요 매체 역시, Opus 4.5가 코딩, 에이전트 워크플로, 복잡한 컴퓨터 작업에서 “세계 최고 수준(best in the world)”을 지향하는 모델이라고 전하며, 리서치, 프레젠테이션, 스프레드시트 같은 일상적 업무 생산성 영역에서도 향상된 성능을 제공한다고 정리합니다. The Times of India+1
또한 Opus 4.5는 Anthropic의 웹·모바일 앱, API뿐 아니라, “세 개의 메이저 클라우드”(Google Cloud, Microsoft, Amazon)를 통해서도 제공된다고 공식 발표 및 기사에서 반복적으로 언급됩니다. Times of India는 이 모델이 Anthropic 앱과 API, 그리고 세 주요 클라우드 플랫폼에서 바로 사용할 수 있다고 명시합니다. The Times of India+1
2. 정확도 – SWE-bench 80.9%가 의미하는 것
2-1. SWE-bench Verified 80.9%
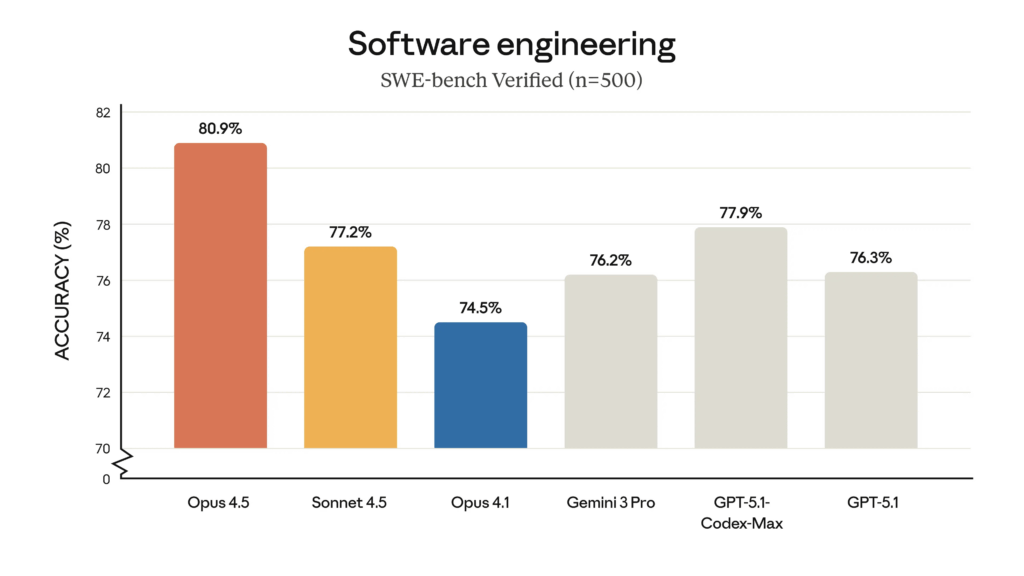
영국 IT 매체 IT Pro는 Opus 4.5를 “새로운 AI 코딩 프런트러너(coding frontrunner)”라고 소개하면서, 이 모델이 소프트웨어 엔지니어링 벤치마크인 SWE-bench Verified에서 정확도 80.9%를 기록했다고 보도합니다. IT Pro
같은 기사에서 IT Pro는 동일 벤치마크 기준으로
- OpenAI GPT-5.1 Codex Max: 77.9%
- Google Gemini 3 Pro: 76.2%
를 언급하며, Opus 4.5가 이들 경쟁 모델보다 높은 점수를 기록했다고 정리합니다. IT Pro
AI 뉴스레터 The Unwind AI 역시 “Claude Opus 4.5 scores 80.9% on SWE-bench Verified, outperforming every other frontier model”이라는 제목으로 같은 수치를 반복 인용하며, 현재 공개된 프런티어 모델 중 최고 수준 성능이라고 평가합니다. theunwindai.com+1
여기서 중요한 포인트는,
“SWE-bench Verified 기준 80.9%”라는 수치 자체는
Anthropic 및 여러 독립 매체에서 일관되게 동일하게 보고된다는 점입니다.
즉, 이 수치만큼은 현재 시점에서 사실로 받아들여도 무방한 공개 정보입니다.
추가로 한국어 블로그 정리 글에서도,
- “2025년 11월 25일 출시된 Opus 4.5는 SWE-bench 80.9%라는 역대 최고 점수를 기록했다”는 요약이 동일하게 반복됩니다. 수월한 연구소
여기까지는 여러 출처에서 일관되게 같은 수치를 가리키기 때문에,
“SWE-bench Verified 기준 80.9%라는 수치는 사실로 받아들여도 무방”
한 상태라고 볼 수 있습니다.
다만,
- 이 시험 자체가 여전히 기업·연구 커뮤니티가 함께 쓰는 벤치마크이지, “정부 공인 시험” 같은 것은 아니라는 점
- 벤치마크 설정(데이터 분할, 평가 방식 등)이 Anthropic 관점에 유리할 가능성도 배제할 수 없다는 점
은 염두에 두어야 합니다.
2-2. 내부 엔지니어링 시험 – “모든 인간 후보보다 높았다”?
Business Insider와 기타 매체는 Anthropic의 내부 2시간 엔지니어링 테스트에서 Opus 4.5가 역대 인간 후보보다 높은 점수를 기록했다고 보도합니다.
- Business Insider 기사: https://www.businessinsider.com/anthropic-claude-opus-4-5-beats-every-human-engineering-test-2025-11 Business Insider+1
하지만 기사 내용을 자세히 보면:
- 모델은 여러 번 시도한 뒤 가장 좋은 답안을 선택하는 방식
- 인간 후보는 단 한 번 시험 본 결과
를 비교한 것입니다.
그래서 이 결과를 정확하게 표현하면,
“Anthropic 내부 설정에서, 여러 번 답을 생성한 Opus 4.5의 최고 성능이
단일 응시 인간 후보들의 최고 성능보다 높았다”
정도로 해석하는 것이 타당합니다.
“AI가 인간 엔지니어를 완전히 능가했다”고 일반화하기에는 정보가 부족합니다.
3. 가격(비용) 구조 – 숫자로 확인되는 변화
Opus 4.5의 가격은 공식 문서·분석 글 다수에서 다음과 같이 정리됩니다.
- 입력: $5 / 1M tokens
- 출력: $25 / 1M tokens
여러 출처에서 같은 숫자를 반복 확인할 수 있습니다.
- Comet 블로그: https://www.cometapi.com/how-much-does-claude-opus-4-5-cost/ CometAPI
- API Dog 블로그: https://apidog.com/blog/claude-opus-4-5-pricing/ apidog
- Simon Willison 개인 블로그 정리: https://simonwillison.net/2025/Nov/24/claude-opus/ Simon Willison’s Weblog
이들 글은 공통적으로, 이전 Opus 4 가격이
- 입력 $15 / 1M
- 출력 $75 / 1M
였다는 점을 언급하면서, Opus 4.5의 $5 / $25 구조는 약 67% 가격 인하에 해당한다고 설명합니다. apidog+1
정리하면,
“SWE-bench 기준 정확도는 올라가고, 토큰 단가(특히 출력)는 약 1/3 수준으로 내려갔다”
라는 것이 현재까지 객관적으로 확인 가능한 포인트입니다.
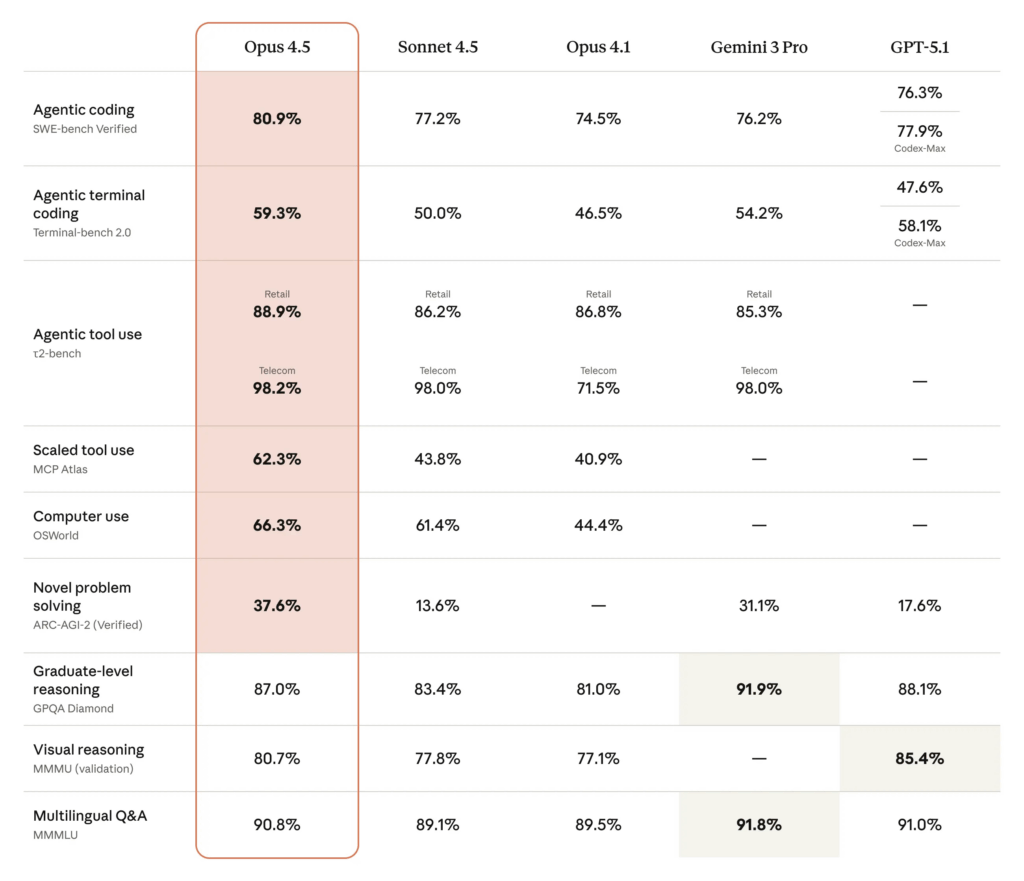
2-2. 코딩·에이전트 벤치마크 전반에서의 위치
Anthropic 공식 발표에 따르면, Opus 4.5는 SWE-bench Multilingual, Aider Polyglot, BrowseComp-Plus, Vending-Bench 등 복수의 코딩·에이전트 벤치마크에서도 이전 세대(예: Sonnet 4.5, Opus 4.1)보다 높은 점수를 기록했다고 설명합니다. Anthropic
세부 수치가 전부 공개된 것은 아니지만, 공식 문서에서
- “7개 언어 중 7개에서 선도적인 코드 성능”
- “에이전트형 검색·장기 작업 벤치에서 의미 있는 점프”
라는 표현을 사용하며, 코딩과 에이전트 태스크 전반에서 상위권 성능을 주장하고 있습니다. Anthropic+1
3. 가격 구조 – Opus 4.1 대비 약 1/3
3-1. 공식·분석 문서 기준 가격
API 가격은 여러 출처에서 거의 동일한 숫자로 반복됩니다.
- Apidog 가격 분석 글: Claude Opus 4.5는
- 입력: 100만 토큰당 5달러
- 출력: 100만 토큰당 25달러
로 책정되며, 이는 이전 Opus 4(입력 15달러, 출력 75달러)에 비해 약 67% 인하라고 설명합니다. apidog+2apidog+2
- Comet, Macaron 등 다른 분석 글도 동일한 가격 구조를 인용하며, Opus 4.5 가격이 Opus 4.1의 1/3 수준으로 떨어졌다고 정리합니다. CometAPI+2Macaron+2
Anthropic의 제품 페이지 역시 “Opus 4.5는 1M 입력 토큰당 5달러, 출력 토큰당 25달러에서 가격이 시작되며, 프롬프트 캐싱과 배치 처리를 통해 추가적인 비용 절감이 가능하다”고 명시합니다. Anthropic
이 정보들을 종합하면,
“Opus 4.5는 이전 Opus 4.1 대비
동일·유사급 성능 범주에서 약 3분의 1 가격으로 책정되었다.”
라는 결론을 비교적 정확하게 말할 수 있습니다.
3-2. 기업 관점에서 해석 가능한 부분(사실 범위 내)
기사와 분석 글들은 공통적으로,
- 기존에는 가격 때문에 “프런티어급 모델”을 일부 핵심 업무에만 제한적으로 썼다면,
- Opus 4.5 가격 인하로 일상적인 프로덕션 워크로드에도 고성능 모델을 적용할 수 있는 여지가 커졌다고 평가합니다. apidog+2apidog+2
여기까지는 “분석 글이 이렇게 평가한다”는 사실을 전달하는 수준이며,
특정 기업의 실제 비용 절감률(예: 40% 절감) 같은 숫자는 공개된 1차 자료를 찾을 수 없으므로 언급하지 않습니다.
4. 어디에 쓰이라고 기사들이 말하고 있나?
4-1. 코딩·소프트웨어 엔지니어링
IT Pro, The New Stack 등은 공통적으로 Opus 4.5를 코딩 특화 LLM 경쟁의 최상위 주자로 소개합니다. IT Pro+2The New Stack+2
대표적으로 언급되는 활용 맥락은 다음과 같습니다.
- 대규모 코드베이스에서의 버그 수정·리팩토링
- 테스트 코드 생성, 코드 리뷰 보조
- 실전형 SWE-bench 과제 해결 능력을 바탕으로 한 엔지니어링 보조/대체 작업
여기까지는 기사들이 직접 명시하는 내용입니다.
“어느 회사에서 버그율이 몇 % 감소했다”와 같은 수치는 아직 공개된 1차 기사에서 찾을 수 없으므로, 의도적으로 다루지 않습니다.
4-2. 에이전트·업무 자동화(Excel, 슬라이드 등)
Business Insider와 기타 매체는 Opus 4.5가 Excel, PowerPoint 같은 오피스 도구와 결합된 업무 자동화에서도 개선된 성능을 보인다고 전합니다. 예를 들어, 재무 분석가 수준의 스프레드시트 생성, 장기 리서치, 슬라이드 초안 작성 등입니다. Business Insider+2IT Pro+2
Google Cloud의 Vertex AI 블로그도, Opus 4.5가
- 복잡한 코딩
- 더 강력한 에이전트
- 엔터프라이즈 애플리케이션 자동화
에 적합한 모델이라고 강조하며, Vertex AI 상에서 통합된 에이전트 빌더 스택과 함께 사용할 수 있다고 설명합니다. Google Cloud+1
5. 안전·사이버보안 이슈 – “막아야 할 때 막는 정확도”
The Verge는 Opus 4.5를 “AI 에이전트 경쟁의 최신 프런티어 모델”이라고 소개하면서도, 사이버보안과 오용(misuse) 위험은 여전히 남아 있다고 지적합니다. The Verge
Anthropic의 시스템 카드 내용을 인용한 해당 기사에 따르면,
- 에이전트형 코딩 평가에서 150건의 악성 코딩 요청을 100% 거절한 테스트 결과가 보고됩니다.
- 그러나 악성 코드 작성, 비윤리적 컴퓨터 작업 같은 다른 영역에서는 거절률이 각각 **78%, 88%**까지 떨어지는 수치도 함께 제시됩니다. The Verge
이 숫자 자체는 “Anthropic 시스템 카드에서 이렇게 보고하고 있다”는 사실을 전하는 것입니다.
즉, Opus 4.5는
- 많은 공격 패턴을 잘 차단하지만,
- 여전히 일부 유형에서는 완벽하지 않다는 점을 Anthropic 스스로 인정하고 있다고 볼 수 있습니다. The Verge
meta_know 인사이트
현재까지 기사와 공식 문서에 나온 정보만 놓고 보면, Claude Opus 4.5는
**“코딩·에이전트 특화 프런티어 LLM 시장에서, 높은 정확도 + 대폭 인하된 가격”**이라는 조합으로 경쟁 구도를 다시 짜고 있습니다.
다만 meta_know 관점에서 중요하게 봐야 할 지점은,
- SWE-bench 80.9%와 토큰 단가 5/25달러는 어디까지나 공개 벤치마크와 가격표이고,
- 각 조직의 코드베이스·업무 프로세스 위에서 체감하는 정확도·비용 효율은 직접 파일럿 테스트를 통해 측정해야 한다는 점입니다.
따라서, Opus 4.5를 포함한 최신 모델들은
“어느 모델이 더 좋은가?”가 아니라
“우리 환경에서 어떤 모델이, 어느 정도 정확도와 비용으로, 어떤 리스크를 가지고 동작하는가?”
라는 질문으로 평가하는 것이 합리적인 다음 단계라고 볼 수 있습니다.
핵심 정리
- Claude Opus 4.5는 Anthropic가 2025년 11월 발표한 플래그십 LLM으로, 코딩·에이전트·컴퓨터 사용에 특화된 모델입니다. Anthropic+1
- 소프트웨어 엔지니어링 벤치마크 **SWE-bench Verified에서 정확도 80.9%**를 기록해, GPT-5.1 Codex Max와 Gemini 3 Pro 등 경쟁 모델보다 높은 점수를 얻었다고 IT Pro와 여러 매체가 보도합니다. IT Pro+2theunwindai.com+2
- API 가격은 입력 100만 토큰당 5달러, 출력 100만 토큰당 25달러로, 이전 Opus 4.1의 1/3 수준까지 인하된 구조입니다. VERTU® Official Site+4apidog+4CometAPI+4
- The Verge 등은 악성 코딩 요청 150건에 대한 100% 거절 성능과 함께, 다른 유형 공격에서의 거절률(78%, 88%)을 지적하며 보안·오용 리스크는 여전히 관리가 필요하다고 평가합니다. The Verge